
Python : A Simple Decision Tree and Random Forest Example
Decision trees are a popular tool in machine learning. They take a form of a tree with sequential questions which leads down a certain route given an answer.
Tree models where the target variable can take a discrete values are called classification trees, whereas when target variable takes continuous values they are called regression trees.
The model takes the form “if this .. then that” conditions to get to a specific outcome. Tree depth is an important concept, it represents how many questions are asked before we reach our result.
Random forests are a collection of decision trees whose results are aggregated into one final result. They are a powerful tool due to their ability to limit over-fitting without substantially increasing error due to bias which is a common case when using decision trees.
We will apply both Decision trees and Random forests models to the famous “kyphosis” dataset. The objective is to determine important risk factors for kyphosis following surgery.
The data was collected on 83 patients undergoing corrective spinal surgery:
-
Kyphosis : with the value “absent” or “present” indicating if a kyphosis was present after the operation.
-
Age : the age in months
-
Number : the number of vertebrae involved
-
Start : the number of the first vertebra operated on
We will use Python in this post, here is the R version. So let´s dive in :).
Preparing the data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
k_data = pd.read_csv('kyphosis.csv')
k_data.head()
| Kyphosis | Age | Number | Start | |
|---|---|---|---|---|
| 0 | absent | 71 | 3 | 5 |
| 1 | absent | 158 | 3 | 14 |
| 2 | present | 128 | 4 | 5 |
| 3 | absent | 2 | 5 | 1 |
| 4 | absent | 1 | 4 | 15 |
k_data.describe()
| Age | Number | Start | |
|---|---|---|---|
| count | 81.000000 | 81.000000 | 81.000000 |
| mean | 83.654321 | 4.049383 | 11.493827 |
| std | 58.104251 | 1.619423 | 4.883962 |
| min | 1.000000 | 2.000000 | 1.000000 |
| 25% | 26.000000 | 3.000000 | 9.000000 |
| 50% | 87.000000 | 4.000000 | 13.000000 |
| 75% | 130.000000 | 5.000000 | 16.000000 |
| max | 206.000000 | 10.000000 | 18.000000 |
We can see that there are 2 missing from the count. It turns out that cases 15 and 28 were removed.
k_data.isnull().values.any()
False
Exploring the Data
To get a quick overlook through our data, we can use the “pairplot” from “seaborn” library, to plot pairwise relationships between the different columns.
import seaborn as sns
sns.pairplot(k_data,hue='Kyphosis')
<seaborn.axisgrid.PairGrid at 0x7f43f4aaeb00>
Training and Testing the Data
# Y
Y = k_data['Kyphosis']
# X
X = k_data.drop('Kyphosis',axis=1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33)
Decision Trees
# Training the model
from sklearn.tree import DecisionTreeClassifier
k_tree = DecisionTreeClassifier()
k_tree.fit(X_train,y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
# Testing and Evaluating the model
k_predictions = k_tree.predict(X_test)
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,k_predictions))
precision recall f1-score support
absent 0.81 0.77 0.79 22
present 0.17 0.20 0.18 5
avg / total 0.69 0.67 0.68 27
print(confusion_matrix(y_test,k_predictions))
[[17 5]
[ 4 1]]
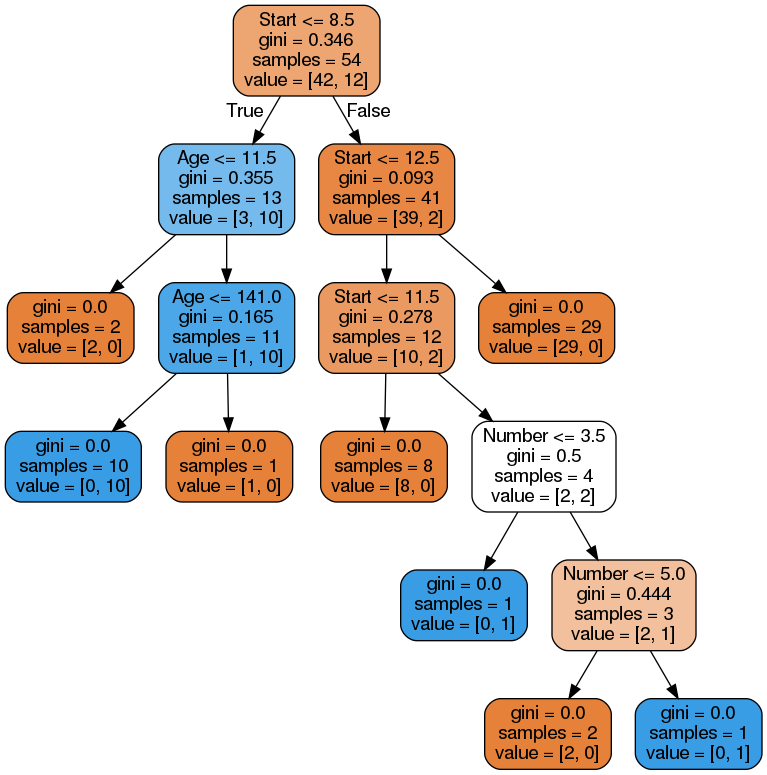
# Visualize the model
import pydot
from IPython.display import Image
from sklearn.externals.six import StringIO
from sklearn.tree import export_graphviz
nms = list(k_data.columns[1:])
dot_data = StringIO()
export_graphviz(k_tree, out_file=dot_data,feature_names=nms,filled=True,rounded=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph[0].create_png())
Random Forests
from sklearn.ensemble import RandomForestClassifier
k_forest = RandomForestClassifier(n_estimators=200)
k_forest.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
kf_predictions = k_forest.predict(X_test)
print(confusion_matrix(y_test,kf_predictions))
[[18 4]
[ 4 1]]
print(classification_report(y_test,kf_predictions))
precision recall f1-score support
absent 0.82 0.82 0.82 22
present 0.20 0.20 0.20 5
avg / total 0.70 0.70 0.70 27